Qt中实现高准确率的语音识别_qt
选择语音识别引擎
开源语音识别项目中,以下两款工具可以用于支持中英文识别,并且与Qt兼容:Vosk:Vosk是一个开源的语音识别工具,支持中英文及多种语言,具备离线识别能力,且不依赖互联网。
PaddleSpeech:PaddleSpeech是百度的开源语音识别工具,准确率较高,但需要稍微多一点的配置。
本示例将使用 Vosk,它支持多平台,且易于集成到C++项目中,满足离线使用、90%以上准确率、开源等要求。Vosk资源下载
首先,下载Vosk的C++库及中英文模型文件:
如果不想编译库,这里有已经编译好的
中英文模型:Vosk 模型下载
下载对应的库和模型,并确保你的开发环境中已经配置好CMake和Qt开发环境。示例代码
以下是一个完整的Qt项目代码示例,展示如何使用Vosk API在C++中进行中英文识别。假设你已经下载并解压了模型文件。
1 |
|
编译与运行
将vosk_api.h和vosk库文件添加到项目中,并在CMakeLists.txt中配置vosk库路径。编译后运行该程序,即可开始录音和实时中英文语音识别。提示
确保麦克风采样率为16kHz,以匹配识别模型的采样率。
运行过程中需要确保模型路径正确,并安装所需的Qt和Vosk依赖库。
参考资源
Vosk官方文档和API:https://alphacephei.com/vosk
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 易锦风的博客!
相关推荐

2025-04-23
Vosk 进行中文语音识别实例_vosk
这个示例展示了如何在 Qt 中集成 Vosk 进行中文语音识别。该示例不仅涵盖了录音的设置与保存,还确保录制的音频文件符合 Vosk 的要求格式。通过 Vosk 的中文模型,我们可以对音频内容进行识别,获取准确的中文转写结果。此外,示例中通过 QString::fromUtf8 来正确解析 Vosk 返回的 UTF-8 编码字符串,确保最终显示的中文内容没有乱码。 示例详细概述 前期准备 在开始编写代码之前,确保已下载 Vosk 库和中文语音模型文件,并将其存放在项目路径中,使程序能够正确加载所需的资源。 功能说明 音频录制:通过 Qt 的 QAudioInput 类,我们设置了一个16kHz采样率、单声道、PCM 编码的录音格式,录制的音频将保存为 .wav 文件,这也是 Vosk 模型所要求的标准音频格式。 语音识别:示例中加载了 Vosk 的中文语音模型,录制完成后将音频文件输入到模型中,由 Vosk 提供的识别器对音频内容进行处理,并生成中文转写结果。 中文字符显示:由于 Vosk 返回的识别结果是 UTF-8 编码的字符串,为了确保 Qt 能正确显示中文,使用...
2025-04-23
语音识别——使用Vosk进行语音识别
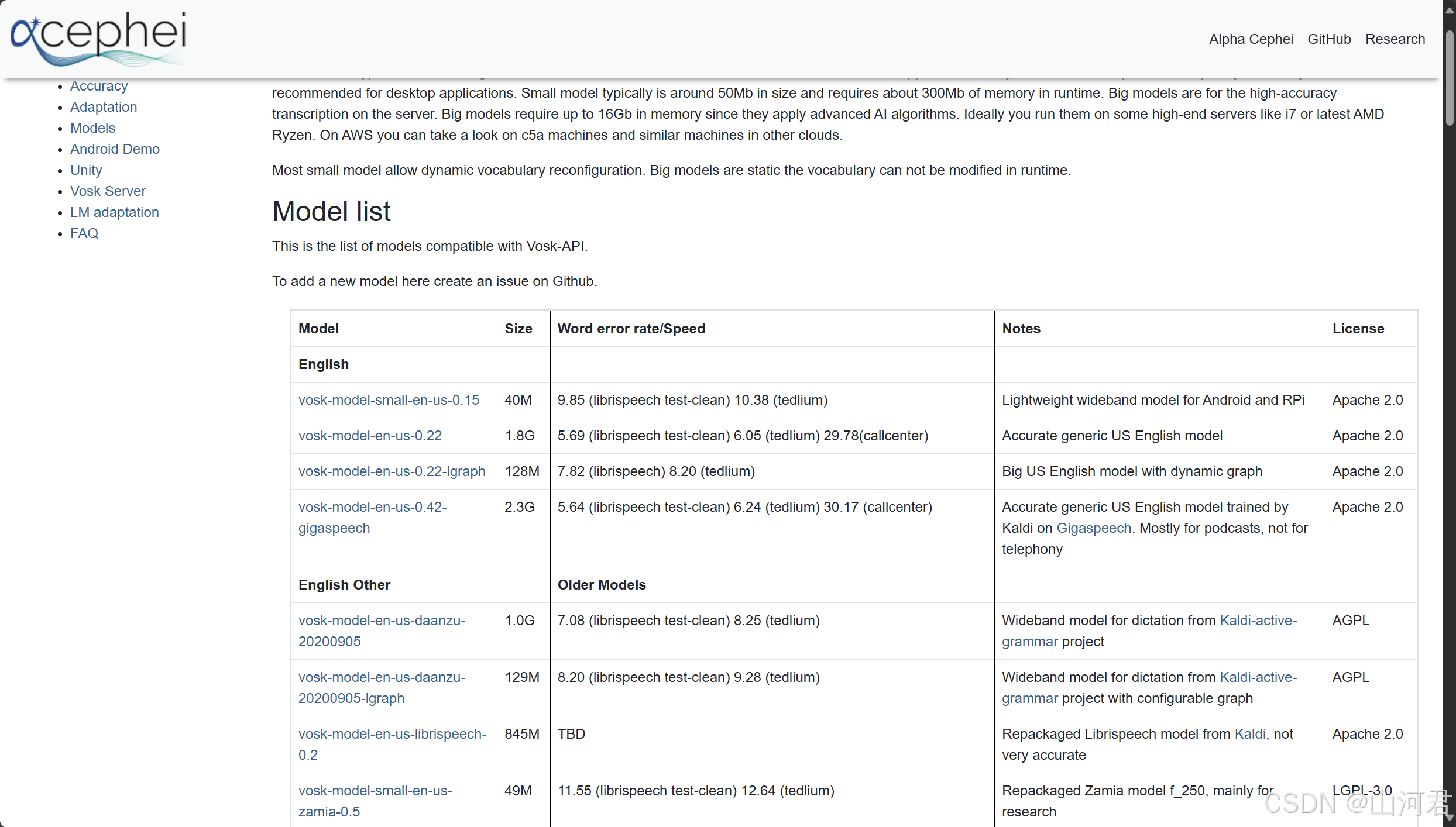
前言 Vosk是语音识别开源框架,支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语, 瑞典语, 日语, 世界语, 印地语, 捷克语, 波兰语, 乌兹别克语, 韩国语, 塔吉克语。 Vosk还支持设备上离线语音识别 ,包括Raspberry Pi,Android,iOS等,API接口简单,并且有多种语言支持,同时会识别语义,最终输出合理的语句。 一、Vosk模型 1.准备好所需要的语音包 在开始使用Vosk之前,需要拥有语音识别的模型,如图中拥有很多语音模型,中文、英文、西班牙、印度等等,Vosk模型库,需要外网才可以下载 2.下载使用 下载并进行解压后如下图所示,例如这里有简单英文、轻量级中文、和用于服务器处理的大型通用中文模型等,根据需要进行下载 解压后放在对应目录下,值得注意的是,是整个解压后的文件夹,而不是某一固定文件,一定要放在对应位置,不然使用时会直接崩溃,连报错都没有。 二、使用示例 ...
2025-07-11
C++11 算法详解:std::copy_if 与 std::copy_n
引言 C++11 标准为算法库带来了诸多增强,其中 std::copy_if 和 std::copy_n 作为 std::copy 的补充,为元素复制操作提供了更精细的控制。这两个算法不仅简化了代码逻辑,还提升了可读性和性能。本文将深入探讨这两个算法的实现细节、使用场景及最佳实践,帮助开发者在实际项目中正确高效地应用它们。 std::copy_if:条件筛选复制 函数原型 12template< class InputIt, class OutputIt, class UnaryPred >OutputIt copy_if( InputIt first, InputIt last, OutputIt d_first, UnaryPred pred ); 核心功能 std::copy_if 从输入范围 [first, last) 中复制满足谓词 pred 的元素到目标范围(始于 d_first),并保持元素的相对顺序。该算法在 C++11 中引入,是对传统 std::copy 的条件化扩展。 ...
2025-07-10
C++之红黑树认识与实现
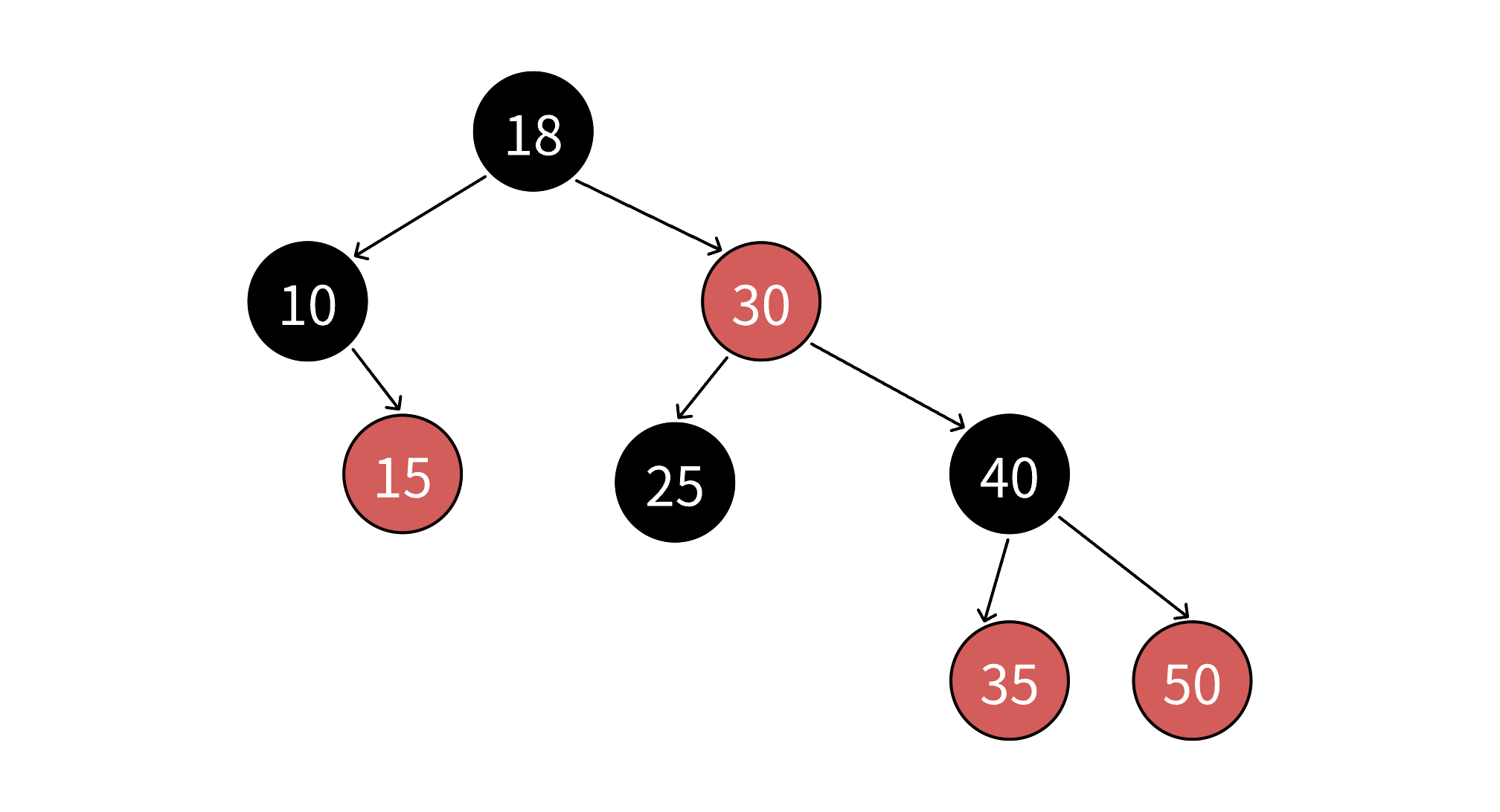
一.红黑树的概念 红⿊树是⼀棵⼆叉搜索树,他的每个结点增加⼀个存储位来表⽰结点的颜⾊,可以是红⾊或者⿊⾊。通过对任何⼀条从根到叶⼦的路径上各个结点的颜⾊进⾏约束,红⿊树确保没有⼀条路径会⽐其他路径⻓出2倍,因⽽是接近平衡的。 红黑树的结构 123456789101112131415161718192021222324252627282930313233343536// 枚举值表⽰颜⾊ enum Colour{ RED, BLACK};template<class K, class V>struct RBTreeNode{ // 这⾥更新控制平衡也要加⼊parent指针 pair<K, V> _kv; RBTreeNode<K, V>* _left; RBTreeNode<K, V>* _right; RBTreeNode<K, V>* _parent; Colour _col; RBTreeNode(const pair<K, V>& kv) :_kv(kv) ,...
2025-07-10
C++动态分配内存知识点!
1.动态分配内存的思想 动态分配内存是指在程序运行时根据需要动态地分配内存空间。这相对于静态分配内存来说,静态分配内存是在编译时固定地分配内存空间,而动态分配内存可以在程序运行期间根据实际需求进行内存的申请和释放,以提高内存的利用率和灵活性。 2.动态分配内存的概念 动态分配内存的概念包括以下几个方面: 2.1内存分配函数 动态分配内存需要使用内存分配函数,如C语言中的malloc()、calloc()、realloc()等,这些函数可以根据需要在运行时动态地分配一块连续的内存空间。 2.2动态内存的申请和释放 使用内存分配函数可以申请一块指定大小的内存空间,申请的内存空间可以在程序运行期间使用。使用完毕后,可以使用释放函数将内存空间释放,以便其他程序继续使用。 2.3内存碎片问题 动态分配内存可能会导致内存碎片问题。当频繁地进行内存分配和释放操作时,可能会在内存中留下一些未被使用的小块内存,这些小块内存无法被再次利用,导致内存的浪费。为了解决内存碎片问题,可以使用内存管理算法来进行内存的分配和释放操作。 ...
2025-01-23
c++之组合、继承、聚合及依赖
在学习c++的过程中相信大家对这几个概念都不陌生。 c++中一些常用的设计模式都是由这几种特性组合而成。本文再从整体对这个概念或者特性进行简要的介绍。 组合 c++中类之间的一种关系叫做"has-a"的关系。这种关系表示的是一个类中包含另一类的对象,体现了“有一个”的关系。这个被包含的类一般以实例对象的形式存在,而非指针对象的形式存在。请看下面的示例: 12345678910111213141516171819class Engine{ public: void start() { cout<<"引擎启动"<<endl; }}class car{private: Engine engine; //这里以实例的形式存在,而非指针,在类关系中是组合的关系public: void startCar() { engine.start(); //启动引擎 }} ...
评论