llama-server启动参数说明文档
1. 概述
llama-server 是 llama.cpp 项目中的一个核心组件,用于将大语言模型(LLM)以 HTTP 服务器的形式发布。通过简单的命令行参数配置,它可以提供包括文本补全、对话补全(Chat Completions)、文本嵌入(Embeddings)和重排序(Reranking)在内的多种功能,并支持多用户并发、推测解码等高级特性。
2. 核心启动参数
llama-server 的参数涵盖了模型加载、服务监听、上下文管理、性能调优以及功能开关等多个方面。以下是一些最常用的参数分类说明。
2.1 模型与基础配置
这是启动服务最基本的参数,用于指定要加载的模型和服务监听地址。

示例:
1 | llama-server -m models/<模型路径> --host 0.0.0.0 --port 8080 |
2.2 上下文管理与并发
这些参数控制模型运行的上下文窗口大小和并发处理能力,直接影响显存占用和服务吞吐量。
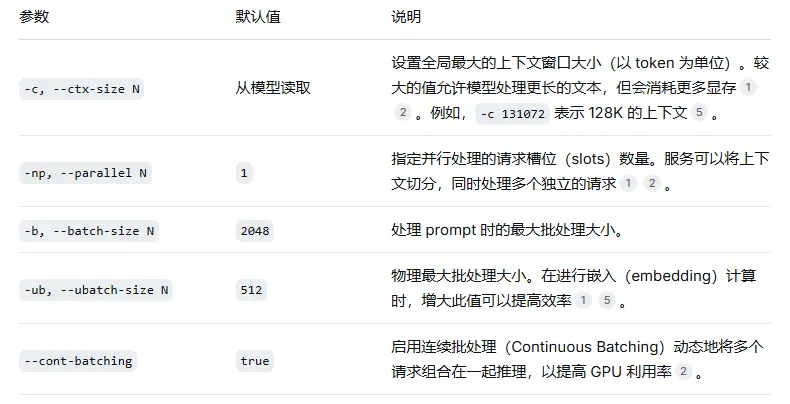
示例:
1 | # 支持4个并发请求,每个请求可用上下文为4096 (总16384/4) |
2.3 采样与控制参数
这些参数用于控制文本生成的随机性和多样性,可以在启动时设置全局默认值。
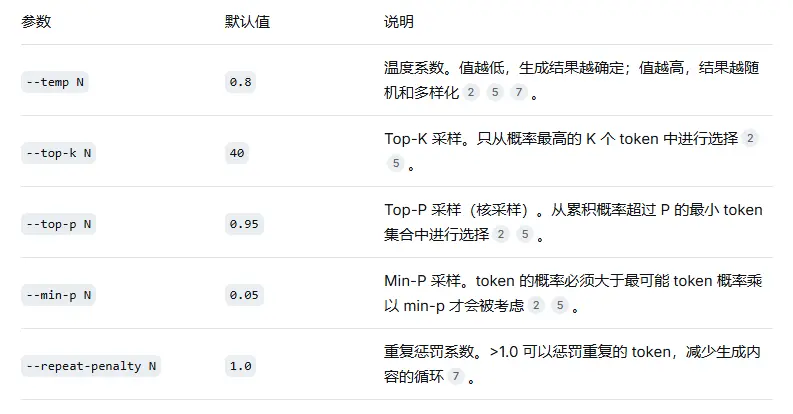
2.4 功能模式开关
llama-server 支持多种运行模式,通过以下参数开启。

示例:
1 | # 启动嵌入模式服务,并使用CLS池化策略 |
2.5 路由模式与多模型管理
从较新版本开始,llama-server 引入了路由模式(Router Mode),允许在一个服务实例中动态管理多个模型。
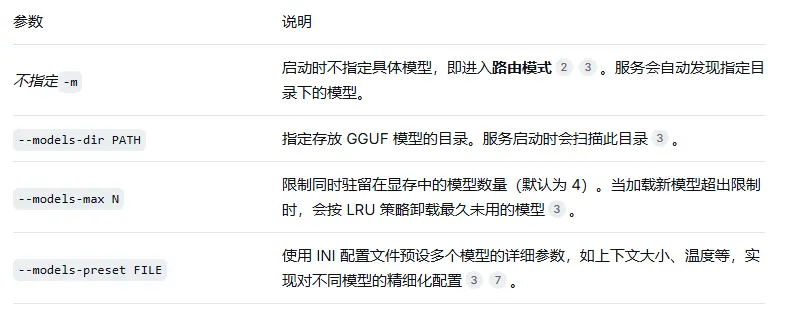
路由模式配置文件 (models.ini) 示例
1 | [model-a] |
示例:
1 | # 启动路由模式,管理./models目录下的模型,最多同时加载2个 |
2.6 硬件优化与高级特性

2.7 安全与认证

2.8 其他实用参数
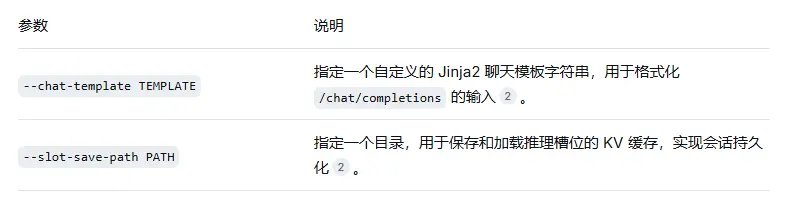
3. 使用示例
3.1 基础聊天服务
启动一个最基础的聊天服务,监听在本地的 8080 端口。
1 | llama-server -m ~/models/llama-3-8b-instruct.Q4_K_M.gguf |
3.2 高性能并发服务
启动一个支持多用户并发、长上下文,并开启 Flash Attention(30系以上n卡支持) 优化的服务。
1 | llama-server -m ~/models/qwen2.5-7b-instruct.Q5_K_M.gguf \ |
通过灵活组合这些参数,你可以根据实际需求和应用场景,将 llama-server 打造成一个高效、稳定的本地大模型推理服务。要获取最完整和最新的参数列表,可以直接在命令行运行 llama-server --help。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 易锦风的博客!
相关推荐
2025-08-25
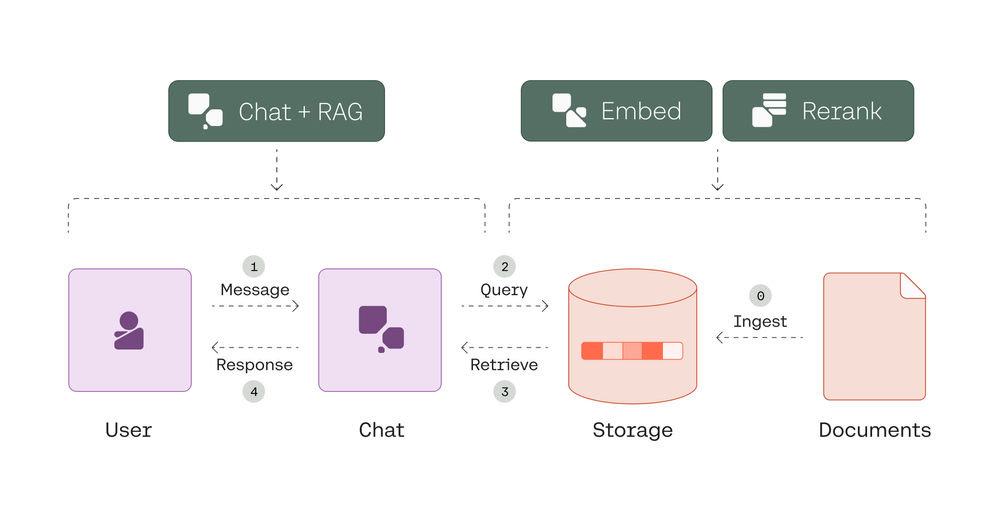
AI探索大模型权重的分类:Chat、Code、Embedding和Rerank
在机器学习和自然语言处理领域,大模型(如GPT-3、BERT等)已经成为了强大且广泛应用的工具。大模型的权重通常可以根据其应用场景分为不同的类别,如Chat、Code、Embedding和Rerank。了解这些分类及其差异对于我们在实际应用中选择合适的模型至关重要。本文将详细讲解这四种权重分类,并说明它们的差异。 1. Chat(对话) Chat模型专注于对话生成和自然语言理解。这些模型经过专门训练,能够理解并生成连贯、自然的对话。Chat模型通常用于客服机器人、虚拟助手等场景。 特点: 自然语言生成:能够生成流畅且有意义的对话。 上下文理解:能够记住对话的上下文并进行相关的回答。 人性化交互:与用户进行类人互动,提供友好的用户体验。 应用场景: 在线客服 智能助手(如Siri、Alexa) 社交媒体聊天机器人 2....

2026-06-17
Qwen3-Coder-30B-A3B-Instruct-IQ4_NL.gguf大模型本地部署指南:从下载到运行全流程(CPU+大内存也能玩转大模型)
一、前提提醒 重点:能纯CPU跑,大概需要26G内存。(我停止运行后,已使用内存从32G降到6G) 也可以CPU+GPU一起跑 大概需要(26G - 显存 × 2)内存 本人刷视频刷到llmfit软件,发现它说我32G内存+8G显存的电脑上能部署千问3 30B这种大模型 我感到非常兴奋,30B啊,这可是30B啊,很久以前我部署过7B大小的模型,那7B真的跟个小学生一样,推理能力差,记忆能力差,输出速度还慢。现在跟我说,我能部署30B的大模型,这我真得尝试尝试了 后面也是成功部署到本地,且推理能力和记忆能力比7B强好多好多,给你们看看实际用了多少内存显存。 下面图片的运行参数是-ngl 16 -c 8192 -t 8(16块专家在显卡上跑,上下文长度8192token,用CPU 8个线程)显存用了7G,内存用了11.5G (i3 12100 RTX2080) cpu+gpu输出速度在11~15 token/s 纯cpu输出速度大概10 token/s 二、准备工作 1.下载 llama.cpp : 官方 GitHub...
2025-04-05
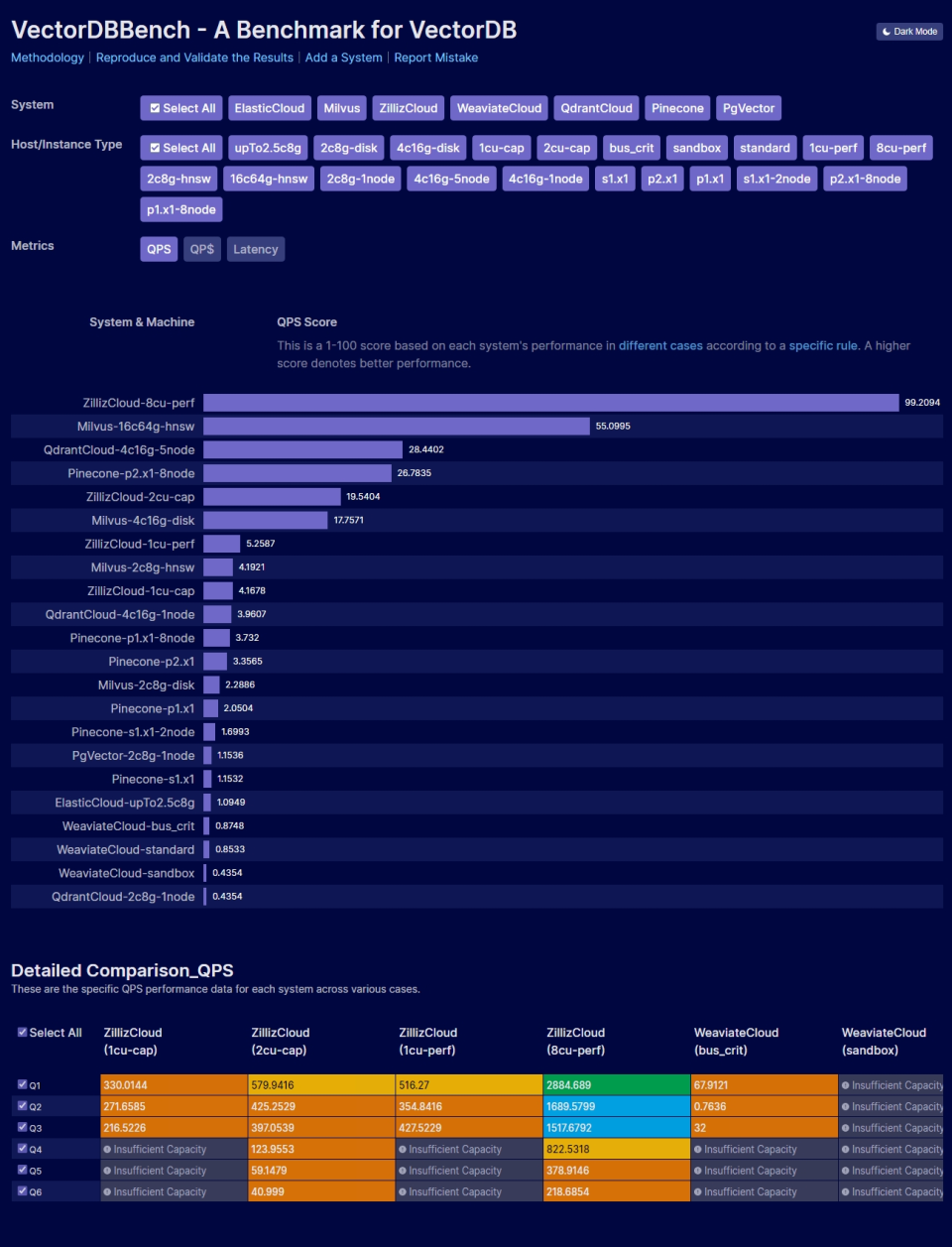
技术人的大模型应用初学指南
Excerpt 随着人工智能技术的快速发展,检索增强生成(RAG)作为一种结合检索与生成的创新技术,正在重新定义信息检索的方式。本文深入探讨了 RAG 的核心原理及其在实际应用中的挑战与解决方案。文章首先分析了通用大模型在知识局限性、幻觉问题和数据安全性等方面的不足,随后详细介绍了 RAG 通过 “检索 + 生成” 模式如何有效解决这些问题。具体而言,RAG 利用向量数据库高效存储与检索目标知识,并结合大模型生成合理答案。此外,文章还对 RAG 的关键技术进行了全面解析,包括文本清洗、文本切块、向量嵌入、召回优化及提示词工程等环节。最后,针对 RAG 系统的召回效果与模型回答质量,本文提出了多种评估方法,为实际开发提供了重要参考。通过本文,读者可以全面了解 RAG 技术的原理、实现路径及其在信息检索领域的革命性意义。 前言 人工智能(AI)时代的到来为技术人员提供了丰富的学习和发展机会。对于没有算法背景的技术同学来说,迎接这种新兴机遇与挑战并做好应对准备和知识储备是非常重要的。 结合笔者这一段对于大模型和 AI 技术的一些学习以及对基于 AI...

2025-07-29
理解模型微调(Fine-tuning) 和 模型蒸馏(Distillation)
大模型蒸馏与大模型微调是当前人工智能领域中两种重要的技术手段,它们在模型优化、性能提升和资源利用方面各有特点。以下将从定义、技术原理、应用场景及优缺点等方面对这两种技术进行深入对比。 一、定义与基本概念 大模型蒸馏(Knowledge Distillation) 蒸馏是一种将大型复杂模型(教师模型)的知识迁移到小型模型(学生模型)的技术。通过训练学生模型模仿教师模型的行为,实现模型压缩和性能保留的目标。蒸馏过程通常包括两个阶段:预训练阶段(教师模型训练)和知识传递阶段(学生模型训练)。 大模型微调(Fine-tuning) 微调是指在预训练的大模型基础上,通过少量标注数据的再训练,使模型适应特定任务的需求。微调可以分为全量微调和参数高效微调(如PEFT)。全量微调适用于需要高精度输出的任务,而参数高效微调则通过优化超参数和调整策略,减少计算资源消耗。 ...

2025-03-21
向量数据库的分类概况_向量库类型
向量数据库的分类概况 保存和检索矢量数据的五种方法: 像 Pinecone 这样的纯矢量数据库 全文搜索数据库,例如 ElasticSearch 矢量库,如 Faiss、Annoy 和 Hnswlib 支持矢量的NoSQL 数据库,例如 MongoDB、Cosmos DB 和 Cassandra 支持矢量的SQL 数据库,例如 SingleStoreDB 或 PostgreSQL 1.纯矢量数据库 纯向量数据库专门用于存储和检索向量。示例包括 Chroma、LanceDB、Marqo、Milvus/Zilliz、Pinecone、Qdrant、Vald、Vespa、Weaviate 等。 在纯矢量数据库中,数据是根据对象或数据点的矢量表示来组织和索引的。这些向量可以是各种类型数据的数值表示,包括图像、文本文档、音频文件或任何其他形式的结构化或非结构化数据。 纯载体数据库的优点 利用索引技术进行高效的相似性搜索 大型数据集和高查询工作负载的可扩展性 支持高维数据 支持基于 HTTP 和 JSON 的...

2025-05-28
靠这九款国产AI大模型,就实现了6亿人的AI梦
2024年 10 月 13 日,工业和信息化部总工程师,赵立国发表讲话:“我国人工智能核心产业的规模在不断提升,企业数量超过了 4500 家,完成注册并提供服务的生成式人工智能服务大模型数量已经超过200个,注册用户数超过了 6 亿。” 这些大模型在各个领域中发挥着重要作用,推动了技术创新和产业变革。 可以看出 2024 年,中国的人工智能技术发展速度真可谓是日新月异,国产AI大模型如雨后春笋般涌现,从 1 月份的 80 多个到 10 月份已经突破超过 200 个,不到十个月时间就激增了 100 多个大模型。 这些大模型中主要以通用大模型 Kimi、智谱清言、通义千问、文心一言、豆包、天工AI、讯飞星火、秘塔和腾讯元宝这九大模型格外引人注目。 在科技大国走向科技强国的号召下,AI 大模型的重要性尤其凸显,这九款国产大模型发展相当出色,它们铸就了中国人我们中国人的 AI 梦。 下面,让我们一起探索这些大模型的特点和面临的挑战,普及和了解它们在AI领域的地位和潜力。 ...
评论

