用Python爬取百度图片:手把手教你写一个图片爬虫
前言
最近想收集一些特定主题的图片素材,手动一张张下载实在太费时间了。作为一个懒人程序员,我决定写个爬虫来自动完成这个任务。今天就跟大家分享这个实用的百度图片爬虫,它能自动搜索并下载你想要的任何图片。
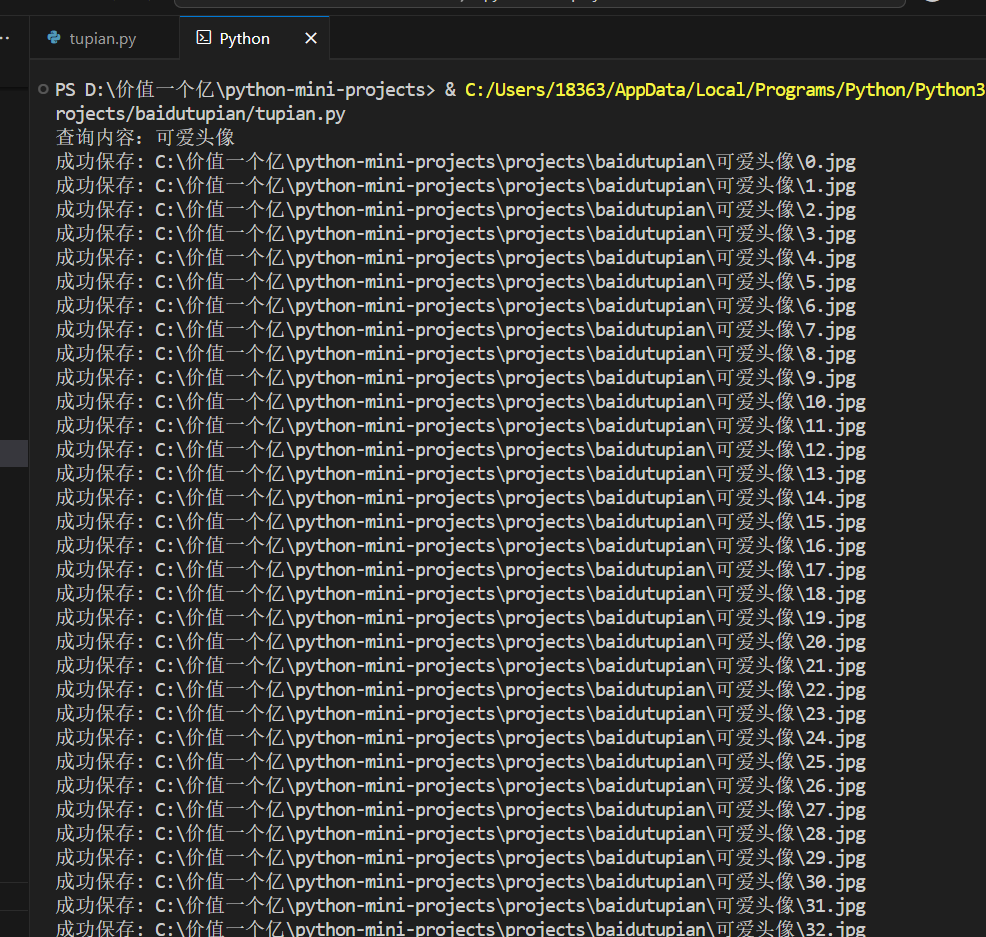

这个爬虫虽然只有100多行代码,但包含了请求处理、JSON解析、文件操作等实用技巧。我会详细解释每个部分的实现思路,让你不仅能使用这个爬虫,还能真正理解它的工作原理。
爬虫整体设计
我们先来看看这个爬虫的总体结构:
1 | class BaiduImageSpider(object): |
这个类包含了爬虫的所有功能,结构清晰,每个方法负责一个具体的任务。接下来我会详细讲解每个部分的实现。
初始化设置
1 | def __init__(self): |
初始化方法中,我们设置了几个重要的变量:
json_count:控制要下载多少组图片(每组30张)url:百度图片的API接口地址,使用格式化字符串方便后续替换关键词directory:图片保存路径,使用{}作为占位符方便后续替换header:请求头,模拟浏览器访问,避免被反爬image_counter:图片计数器,用于生成唯一的文件名
创建保存目录
1 | def create_directory(self, name): |
这个方法负责创建保存图片的文件夹:
- 使用
format方法将搜索关键词插入到路径中 os.makedirs创建目录,exist_ok=True表示如果目录已存在也不报错- 最后在路径后添加
\{},方便后续格式化文件名
获取图片链接
1 | def get_image_link(self, url): |
这是爬虫的核心方法之一,负责从百度API获取图片链接:
- 使用
requests.get发送HTTP请求 - 设置了请求头和代理(这里禁用了代理)
- 添加了10秒超时设置
raise_for_status()会在请求失败时抛出异常- 使用列表推导式从返回的JSON中提取所有
thumbURL字段 - 添加了异常处理,失败时打印错误信息并返回空列表
下载并保存图片
1 | def save_image(self, img_link, filename): |
这个方法负责下载并保存图片:
- 同样使用
requests.get获取图片内容 - 以二进制写入模式(
wb)打开文件 - 直接将响应内容写入文件
- 添加了异常处理,下载失败时打印错误信息
主运行逻辑
1 | def run(self): |
这是爬虫的主控制流程:
- 获取用户输入的搜索关键词
- 对关键词进行URL编码
- 创建保存目录
- 重置图片计数器
- 循环获取多组图片(每组30张)
- 构建请求URL,
pn参数控制分页 - 获取图片链接列表
- 逐个下载图片,文件名使用递增的数字
- 每次下载后暂停1秒,避免请求过于频繁
- 完成后打印提示信息
扩展思路
这个基础爬虫还可以进一步扩展:
支持更多搜索引擎:除了百度,还可以添加谷歌、必应等图片搜索的支持
图片筛选:根据大小、格式、颜色等条件筛选图片
去重功能:使用哈希值检查避免下载重复图片
断点续传:记录已下载的图片,程序中断后可以从中断处继续
GUI界面:使用PyQt或Tkinter添加图形界面,更方便非技术人员使用
完整代码
1 | import requests |
使用说明
- 安装依赖:
1 | pip install requests |
运行方式:
- 直接运行:
tupian.py - 或者导入使用:
if name == ‘main’:
spider = BaiduImageSpider()
spider.json_count = 10 # 下载10组图片
spider.run()- 直接运行:
创建爬虫实例
设置
json_count决定下载多少组图片(每组30张)调用
run()方法开始爬取
运行后会提示输入搜索关键词,然后就会自动下载图片到指定目录。

高级技巧
- 代理设置:如果需要使用代理,可以修改请求方法:
1 | proxies = { |
- 多线程下载:可以使用
concurrent.futures实现:
1 | from concurrent.futures import ThreadPoolExecutor |
- 断点续传:记录已下载的URL,程序重启后跳过已下载的图片。
注意事项
- 请遵守百度的robots.txt协议,合理控制请求频率
- 不要用于商业用途,尊重图片版权
- 建议设置合理的
json_count值,避免请求过多被封IP - 下载失败时,程序会自动重试,但大量失败可能是触发了反爬机制
这个改进版的百度图片爬虫具有更好的稳定性、更详细的日志输出和更友好的使用体验。你可以根据自己的需求进一步扩展功能,比如添加图片去重、自动分类等功能。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 易锦风的博客!
相关推荐

2025-04-16
PyPy、Numba 与 Cython,哪个是最佳 Python运算解决方案?
正如Python之父说:“大部分觉得Python慢的应用都是没有正确地使用Python。” 由于Python由于要在运行时编译和解释执行字节码,而且这个过程中参与了很多类似运行时类型检查的操作等一系列其他操作,从而产生了很多额外开销,降低了性能。 为了让这门语言变得完美,PyPy、Numba、Cython解决方案应用而生。 PyPy PyPy是用RPython(CPython的子集)实现的Python,根据官网的基准测试数据,它比CPython实现的Python要快6倍以上。快的原因是使用了Just-in-Time(JIT)编译器,即动态编译器,与静态编译器(如gcc,javac等)不同,它是利用程序运行的过程的数据进行优化。 **适用场景:**PyPy最适合纯Python应用程序,不适用于C扩展 Numba Numba 是 python 的即时(Just-in-time)编译器,即当您调用 python 函数时,您的全部或部分代码就会被转换为“即时”执行的机器码,它将以您的本地机器码速度运行。 python 代码的编译过程包括四个阶段:词法分析 -> 语法分析...

2025-09-07
Anaconda安装与使用详细教程
这篇 Anaconda 安装教程将带你从零开始,在 Windows 与 Linux 上完美部署 Python 数据分析环境;通过本教程,你不仅能掌握 Anaconda 的下载、安装与环境配置,更能学会如何利用 Anaconda 预装的 NumPy、Pandas、Matplotlib 等核心科学计算包,为高效的数据处理与分析工作打下坚实基础。 Anaconda 是一个开源的 Python 和 R语言的发行版本,专为科学计算(数据科学、机器学习、大规模数据处理等)而设计。它极大地简化了包管理和环境管理的过程。Anaconda 预装了 conda、Python 以及数百个常用的科学计算、数据分析相关的包,如 NumPy, Pandas, Scikit-learn, Matplotlib 等,让你无需再为繁琐的依赖问题而烦恼。 关于下载 官网:https://www.anaconda.com/download 国内镜像源...

2025-08-13
Python 环境管理新标杆:UV核心命令完全指南
UV工具定位:极速Python环境管理 UV是Astral团队开发的下一代Python环境管理工具,其核心优势在于: ⚡ 速度革命:依赖解析比pip快10-100倍 🪶 轻量设计:环境创建仅需0.05秒 🔒 安全可靠:内置依赖锁定机制 🔄 无缝迁移:兼容现有pip工作流 安装命令:pipx install uv(推荐)或 pip install uv 核心命令详解手册 1. uv venv:闪电环境创建 功能:创建轻量级虚拟环境 1234567891011# 基础用法(默认创建.venv)uv venv# 指定Python版本uv venv --python 3.11# 包含系统包(类似--system-site-packages)uv venv --system# 自定义路径uv venv --path ~/envs/project-env 环境结构: 12345678.venv/├── bin # Unix可执行文件│ ├── python│ ├── pip├── Scripts # Windows可执行文件│ ...
2025-09-14
Windows上将Eex部署成为服务WinSW和NSSM
使用Windows,经常需要将带界面的Windows 应用、exe可执行程序、bat批处理文件变为Windows服务,以便于后台运行,支持开启重启、进程保护等功能。 有众多的工具支持将exe文件封装为Windows服务,常用的工具包括: Sc.exe/NSSM/WinSW/Shawl/AlwaysUp/FireDaemon Sc.exe https://learn.microsoft.com/zh-cn/windows/win32/services/controlling-a-service-using-sc Windows系统内置命令,需要熟悉命令行操作,对新手不友好 以前还有SRVANY.exe,微软官方在 Windows 10/11 上已经不再提供支持,因此不推荐。 NSSM https://nssm.cc/builds https://github.com/kirillkovalenko/nssm 开源,功能强大,但从2017年以后未再更新维护 ...
2025-03-09
Python虚拟环境创建和使用方法(使用自带的venv模块)
概要 这篇文章主要如何在Python中使用虚拟环境,包括创建、激活、使用、生成requirements.txt文件、卸载包和删除虚拟环境,虚拟环境有助于隔离项目依赖,避免版本冲突,并便于部署,需要的朋友可以参考下 1. 安装虚拟环境工具 从 Python 3.3 开始,Python 自带了 venv 模块,无需额外安装。你可以直接使用它来创建虚拟环境。 2. 创建虚拟环境 2.1 使用 venv 创建虚拟环境 使用以下命令创建虚拟环境。这里我使用了 venv 来创建虚拟环境,并且命名为 venv,你也可以选择任何其他名称。 python -m venv myvenv python -m venv myvenv:这条命令会在当前目录下创建一个名为 myvenv 的虚拟环境和文件夹。 如果你有多个 Python 版本,你可能需要指定 Python 版本,如 python3.8 或 python3,以确保使用正确的版本。 2.2 查看虚拟环境文件 虚拟环境创建后,会在当前目录下生成一个...
2025-07-22
c++和python的互相调用
前提 因项目需求,需要在C++中调用python,对这方面的一些工具做个简单的介绍。 ctypes ctypes 是 Python 的外部函数库。它提供了与 C 兼容的数据类型,并允许调用 DLL 或共享库中的函数。可使用该模块以纯 Python 形式对这些库进行封装。 上面是ctypes官方文档给出的介绍,通俗理解来说:ctypes可以加载动态链接库,然后以此调用动态链接库中的函数。也就是说,如果我们有一个.c文件,我们可以将它编译成库,然后在python代码里面使用ctypes加载调用它。 相关代码如下: 创建一个main.c文件,包括三个函数,等会我们要通过调用动态链接库的方式在python中调用这三个函数。 123456789101112131415// main.c#include <stdio.h>#include <stdlib.h>int add(int a, int b) { return a + b;}int sum(int *a, int num){ int sum = 0; ...
评论


