这个示例展示了如何在 Qt 中集成 Vosk 进行中文语音识别。该示例不仅涵盖了录音的设置与保存,还确保录制的音频文件符合 Vosk 的要求格式。通过 Vosk 的中文模型,我们可以对音频内容进行识别,获取准确的中文转写结果。此外,示例中通过 QString::fromUtf8 来正确解析 Vosk 返回的 UTF-8 编码字符串,确保最终显示的中文内容没有乱码。
示例详细概述
前期准备
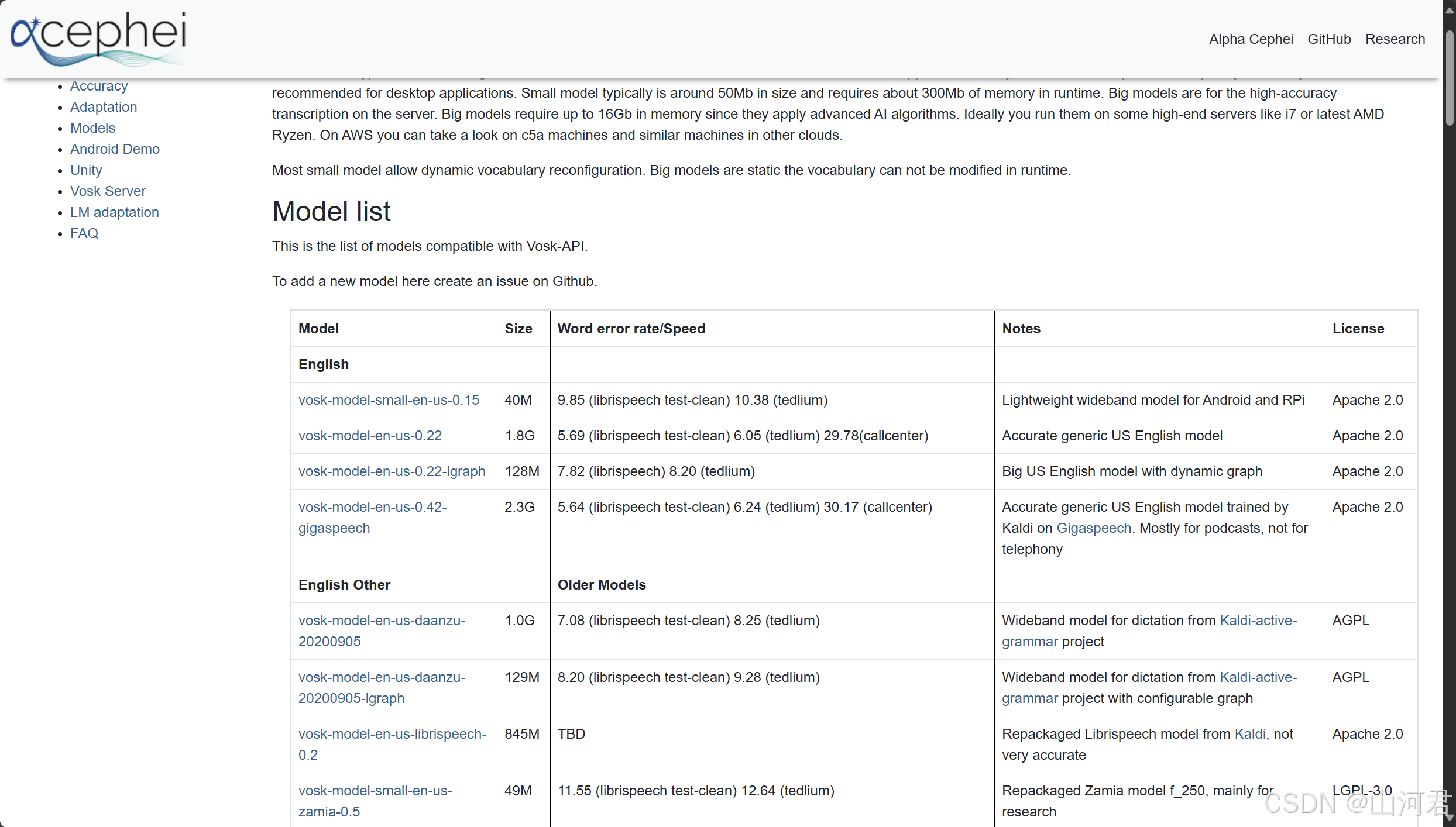
在开始编写代码之前,确保已下载 Vosk 库和中文语音模型文件,并将其存放在项目路径中,使程序能够正确加载所需的资源。
功能说明
音频录制:通过 Qt 的 QAudioInput 类,我们设置了一个16kHz采样率、单声道、PCM 编码的录音格式,录制的音频将保存为 .wav 文件,这也是 Vosk 模型所要求的标准音频格式。
语音识别:示例中加载了 Vosk 的中文语音模型,录制完成后将音频文件输入到模型中,由 Vosk 提供的识别器对音频内容进行处理,并生成中文转写结果。
中文字符显示:由于 Vosk 返回的识别结果是 UTF-8 编码的字符串,为了确保 Qt 能正确显示中文,使用 QString::fromUtf8 将识别结果解析成 QString 类型。这样可以避免乱码,使最终的中文文本能够正确显示在控制台或界面中。
通过以上几个步骤,整个流程能够将录制的中文音频文件成功转换为文本,并正确显示。
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
| #include <QCoreApplication>
#include <QAudioInput>
#include <QFile>
#include <QTimer>
#include <QDebug>
#include <vosk_api.h>
#include <iostream>
class AudioRecorder : public QObject {
Q_OBJECT
public:
AudioRecorder(QObject *parent = nullptr) : QObject(parent), audioFile("recorded_audio.wav") {
QAudioFormat format;
format.setSampleRate(16000);
format.setChannelCount(1);
format.setSampleSize(16);
format.setCodec("audio/pcm");
format.setByteOrder(QAudioFormat::LittleEndian);
format.setSampleType(QAudioFormat::SignedInt);
audioInput = new QAudioInput(format, this);
if (!audioFile.open(QIODevice::WriteOnly | QIODevice::Truncate)) {
qWarning() << "无法打开文件进行录音";
return;
}
}
void startRecording(int durationMs) {
audioInput->start(&audioFile);
qDebug() << "开始录音...";
QTimer::singleShot(durationMs, this, &AudioRecorder::stopRecording);
}
signals:
void recordingFinished();
public slots:
void stopRecording() {
audioInput->stop();
audioFile.close();
qDebug() << "录音完成";
emit recordingFinished();
}
private:
QAudioInput *audioInput;
QFile audioFile;
};
class SpeechRecognizer : public QObject {
Q_OBJECT
public:
SpeechRecognizer(const QString &modelPath, QObject *parent = nullptr) : QObject(parent) {
model = vosk_model_new(modelPath.toStdString().c_str());
if (model == nullptr) {
qWarning() << "无法加载模型";
}
}
~SpeechRecognizer() {
vosk_model_free(model);
}
void recognize(const QString &audioFilePath) {
VoskRecognizer *recognizer = vosk_recognizer_new(model, 16000.0);
FILE *audioFile = fopen(audioFilePath.toStdString().c_str(), "rb");
if (audioFile == nullptr) {
qWarning() << "无法打开音频文件";
vosk_recognizer_free(recognizer);
return;
}
char buffer[4096];
int bytesRead;
while ((bytesRead = fread(buffer, 1, sizeof(buffer), audioFile)) > 0) {
if (vosk_recognizer_accept_waveform(recognizer, buffer, bytesRead)) {
QString result = QString::fromUtf8(vosk_recognizer_result(recognizer));
qDebug() << "识别结果:" << result;
} else {
QString partial = QString::fromUtf8(vosk_recognizer_partial_result(recognizer));
qDebug() << "部分识别:" << partial;
}
}
QString finalResult = QString::fromUtf8(vosk_recognizer_final_result(recognizer));
qDebug() << "最终结果:" << finalResult;
fclose(audioFile);
vosk_recognizer_free(recognizer);
}
private:
VoskModel *model;
};
int main(int argc, char *argv[]) {
QCoreApplication app(argc, argv);
QString modelPath = QApplication::applicationDirPath() + "/vosk-model-cn";
SpeechRecognizer recognizer(modelPath);
AudioRecorder recorder;
QObject::connect(&recorder, &AudioRecorder::recordingFinished, [&recognizer]() {
QString audioFilePath = QApplication::applicationDirPath() + "/recorded_audio.wav";
recognizer.recognize(audioFilePath);
});
recorder.startRecording(5000);
return app.exec();
}
|
详细说明
音频录制:AudioRecorder 类负责音频的录制。它使用了 Qt 的 QAudioInput 类,并将音频设置为符合 Vosk 要求的16kHz采样率、单声道、PCM格式。这种设置使得录制的音频文件适合直接输入给 Vosk 进行处理。录音结束后,音频数据会被保存到 recorded_audio.wav 文件中,便于后续的语音识别步骤使用。
语音识别:SpeechRecognizer 类负责将录制好的音频文件输入到 Vosk 的中文语音模型中进行识别。它通过 Vosk 提供的 API 加载中文模型,将音频文件内容转换为文本信息。为了确保中文字符正确显示,我们使用 QString::fromUtf8 来处理 Vosk 返回的 UTF-8 编码的识别结果字符串,从而避免了乱码问题。
主程序逻辑:在主程序中,我们创建了 AudioRecorder 实例来启动录音操作。当录音结束后,程序会自动触发 SpeechRecognizer 的识别流程,并将识别的中文文本结果输出到控制台。
编译与运行
准备工作:将 Vosk 的中文模型和所需的库文件放置在项目目录下,同时确保在项目配置中添加了 Vosk 库的路径和头文件路径,以便正确链接 Vosk 库。
编译与运行程序:完成项目配置后,编译并运行程序。启动后,程序将录制5秒钟的音频并保存文件,然后调用 Vosk 模型进行语音识别。识别结果将通过 qDebug() 输出到控制台,显示音频中识别出的中文内容。
注意事项
音频格式:录制的音频文件必须符合16kHz采样率、单声道、PCM格式的要求,这是 Vosk 模型所能处理的标准格式。其他格式可能会导致识别失败或不准确。
中文编码:Vosk 返回的识别结果是 UTF-8 编码的,为避免乱码问题,使用 QString::fromUtf8 来解析结果,从而正确显示中文字符。
输出路径:确保模型文件路径和音频文件路径在代码中正确设置,使程序能够顺利加载中文模型和录制的音频文件,从而完成整个语音识别过程。
Demo下载