如何在本地部署Ollama大模型并使用Python进行简单访问
如何在本地部署Ollama大模型并使用Python进行简单访问
简介
Ollama是一个强大的大型语言模型平台,它允许用户轻松地下载、安装和运行各种大型语言模型。在本文中,我将指导你如何在你的本地机器上部署Ollama,并展示如何使用Python进行简单的API调用以访问这些模型。
步骤1:下载和安装Ollama
首先,访问Ollama官网下载Ollama。安装过程非常简单,只需遵循安装向导的指示即可。默认情况下,Ollama会安装在系统的默认路径下。
更改模型保存路径
如果你想更改模型的保存路径,可以通过设置系统环境变量来实现。创建一个名为OLLAMA_MODELS的环境变量,并将其值设置为你希望保存模型的路径。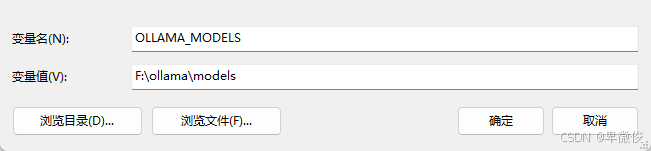
步骤2:验证Ollama安装
安装完成后,打开命令提示符(cmd)并输入ollama来验证Ollama是否安装成功。如果安装成功,你将看到Ollama的启动界面。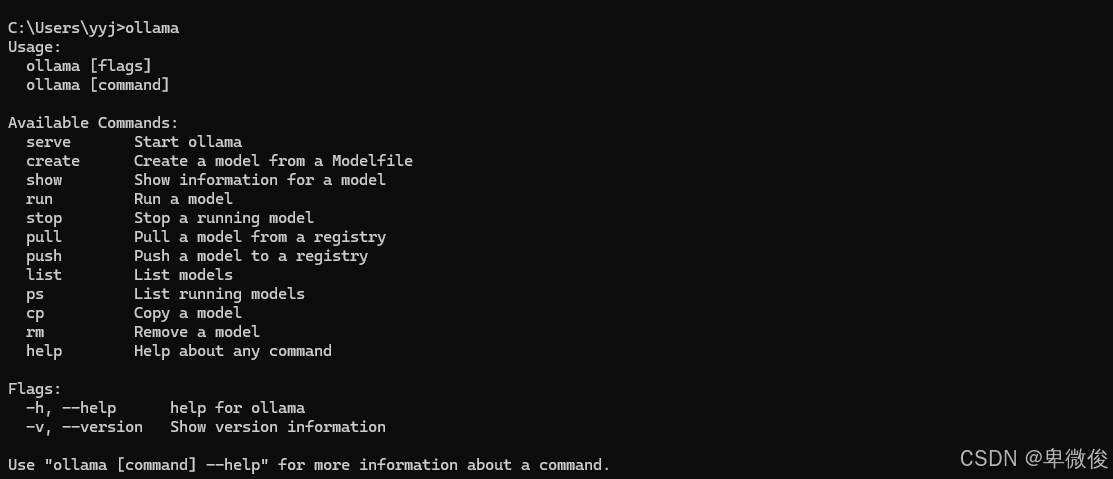
步骤3:选择并下载模型
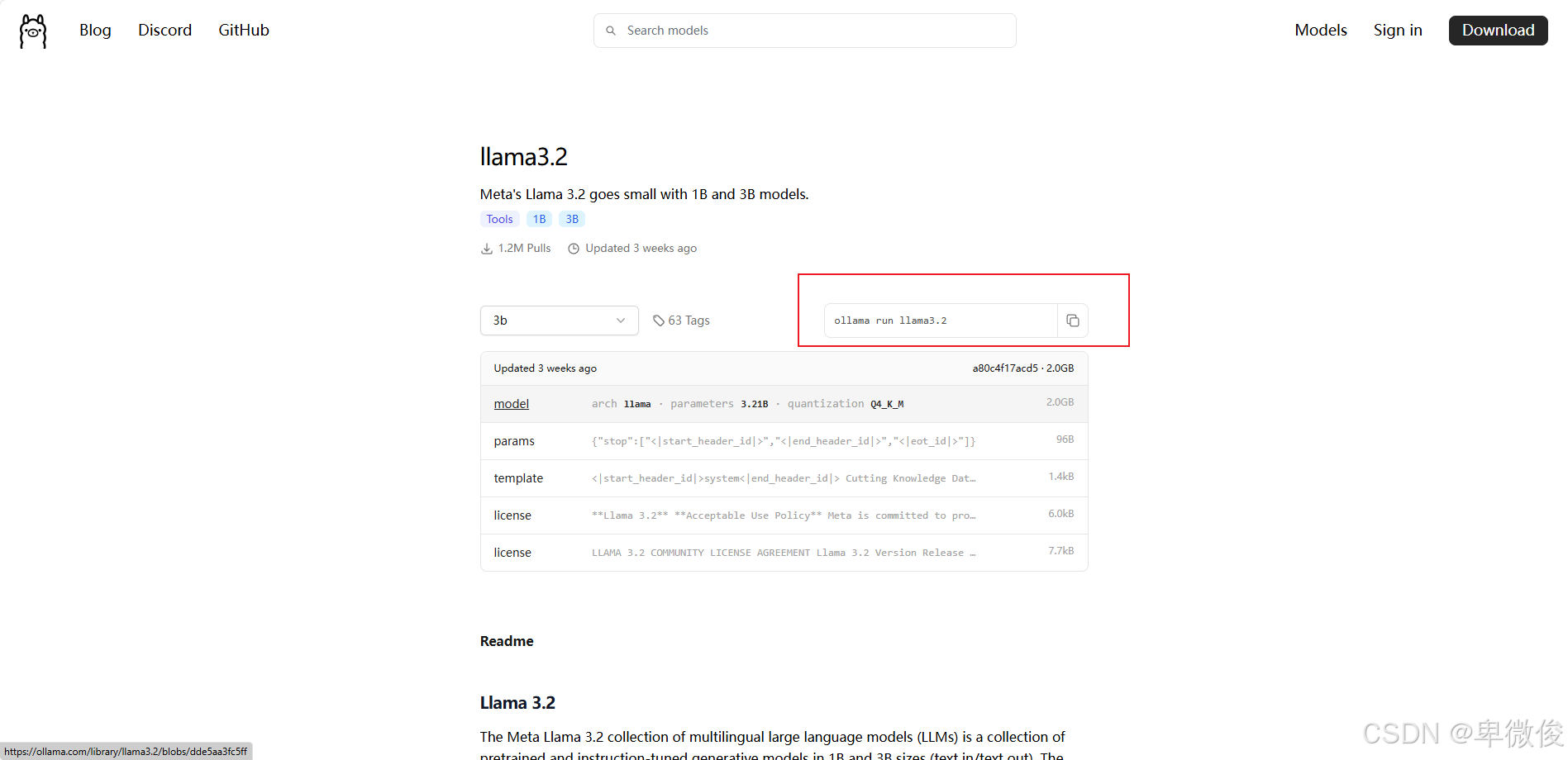
接下来,访问Ollama模型库来浏览和选择你需要的模型。在这个例子中,我选择了llama3.2模型。复制模型页面上提供的代码ollama run llama3.2,并将其粘贴到cmd中运行。Ollama将开始下载模型文件,并在下载完成后自动运行。你可以通过输入/bye来退出对话。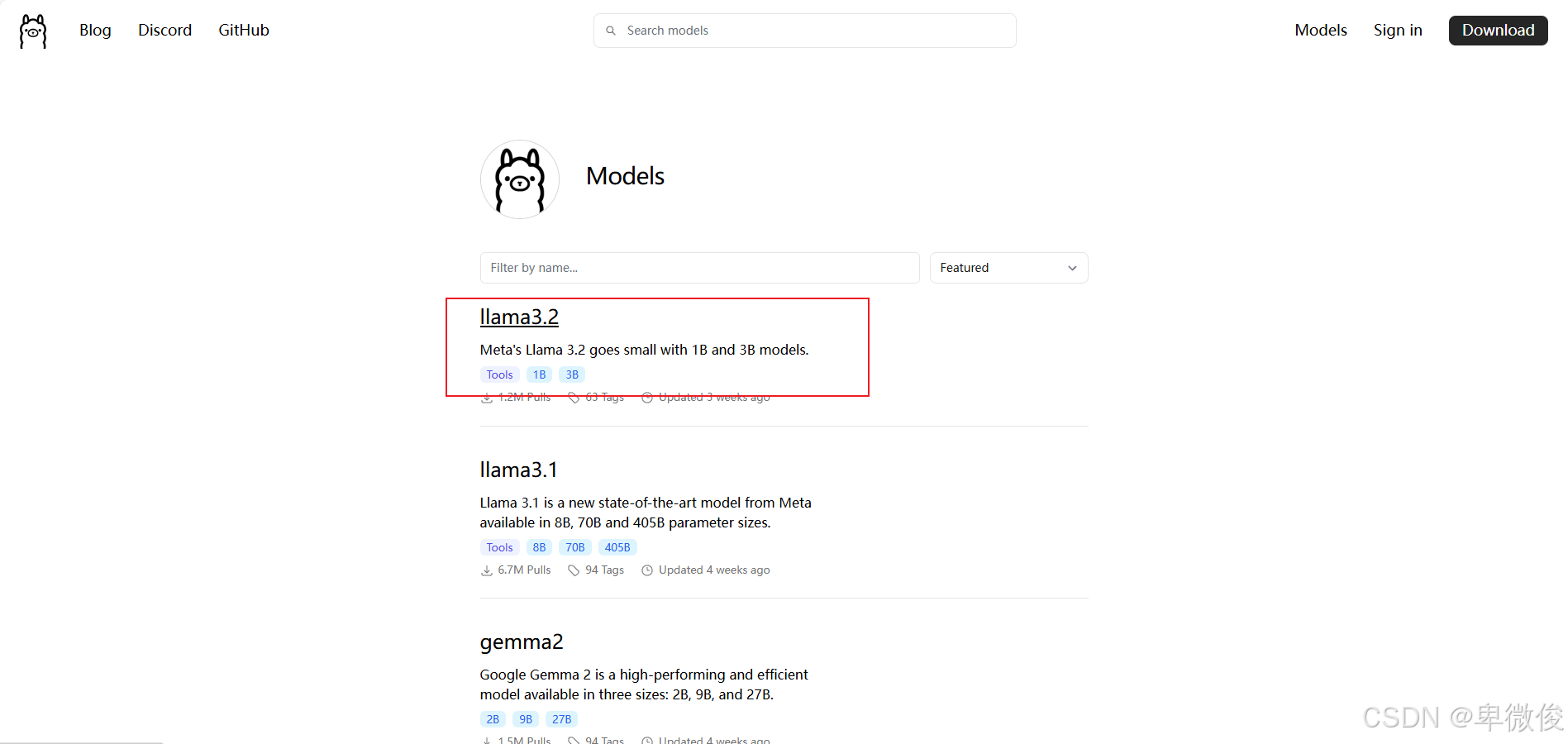
步骤4:使用Python访问本地Ollama
为了使用Python访问本地运行的Ollama模型,首先需要启动Ollama的服务器模式。在cmd中输入ollama serve并运行。Ollama服务器将启动,并在日志中显示访问路径,通常类似于http://localhost:11434/api/chat。
Python访问代码示例
以下是一个Python代码示例,展示了如何使用requests库向Ollama服务器发送请求,并获取响应。
1 | import requests |
这段代码首先设置了API的URL和输入文本,然后定义了要发送的数据结构,包括模型名称、消息列表和是否流式传输。在消息列表中,我们特别关注角色为user的消息,并将其内容设置为我们的输入文本。然后,我们将数据结构转换为JSON格式,并使用requests库发送POST请求。最后,我们打印出服务器的响应内容。
通过以上步骤,你可以轻松地在本地部署Ollama大模型,并使用Python进行简单的API调用。这为开发基于大型语言模型的应用提供了一个强大的平台。